
Traçabilité des enregistrements, imports et exports
Edition en lot
Le module Édition en lot permet de modifier un ou plusieurs champs sur plusieurs enregistrements à la fois. Toutes les éditions en lot sont journalisées dans un log afin d'en garantir la traçabilité.
Pour effectuer une édition en lot, il faut au préalable définir les champs d'un objet sur lesquels l'utilisateur pourra agir. Comme chaque objet possède des champs qui lui sont propres, il faudra paramétrer une édition en lot pour chaque objet : produit, partenaire, ressource, écriture comptable, ... Cette fonction peut être limitée à des utilisateurs ou à un groupe d'utilisateurs.
Ajouts du module
Le module ajoute :
-
Un objet « édition en lot » (mass_object) permettant de créer des actions d'édition en lot ;
-
Un menu Édition en lot contenant deux sous-menus ;
-
Un sous-menu Édition en lot pour gérer les actions d'édition en lot ;
-
Un sous-menu Log d'édition pour consulter les modifications effectuées.
Configuration d'une édition en lot
Les éditions en lot sont gérées depuis le sous-menu Configuration / Édition en lot / Édition en lot, qui affiche la liste les éditions en lot.
Les éditions en lot ne sont pas créées par défaut. Elles sont liées à un objet, il faudra donc en créer autant qu'il y a d'objets à modifier en masse.

 Formulaire d'édition de lot
Formulaire d'édition de lot
En-tête
Une édition en lot porte un nom et agit sur un modèle d'objet.
Pour trouver le modèle, il faut entrer le nom français de l'objet ou le nom exact de la table correspondante. Par exemple, pour créer une édition en lot sur les partenaires, on peut saisir « res.partner » ou « partenaire ».
L'édition en lot apparaîtra dans le menu actions situé dans le bandeau supérieur des vues de l'objet sélectionné, sous son nom. Dans l'interface, l'action apparaîtra sous le nom « Édition en lot (nom) ».
Il est conseillé d'appeler l'édition en lot par le nom de l'objet édité. Par exemple, « Partenaires » pour les partenaires : le nom affiché sera ainsi « Édition en lot (Partenaires) ».
Onglet « Champs »
Cet onglet contient la liste des champs modifiables en lot : seuls ces champs seront affichés lors de l'action. on ajoutera donc uniquement les champs qu'on souhaite rendre modifiables en masse.
Il est recommandé de bien étudier les effets de bord à l'activation de l'édition de lot sur un champ, et d'ajouter uniquement les champs nécessaires, quitte à en ajouter plus tard. La plupart du temps, l'édition en lot répond à un besoin précis qui demande d'agir sur un champ.
Onglet « Sécurité »
Cet onglet liste les utilisateurs et les groupes autorisés à utiliser l'édition en lot. Tous les utilisateurs/groupes d'utilisateurs auront accès à la même action ; l'attribution d'options différentes est expliquée plus bas
Pour que l'édition en lot apparaisse aux utilisateurs, il faut cliquer sur le bouton ajouter action après le paramétrage.
Utilisation
Une fois l'action ajoutée, l'édition en lot est accessible depuis la vue liste de la table (ou objet) définie dans le champ modèle. L'édition s'effectue sur une sélection d'enregistrements : l'utilisateur utilisera les filtres et regroupements pour lister les enregistrements à éditer avant de sélectionner les enregistrements puis de cliquer sur le bouton action en haut de la liste. Cliquer sur l'action qui s'appelle « Édition en lot [nom donné] ». Un assistant s'affiche (cf. illustration ci-contre).
Pour modifier un champ, il faut choisir SET puis entrer la nouvelle valeur à appliquer, ou REMOVE pour supprimer la valeur actuelle sans la remplacer (ou SET en laissant la valeur vide).
Il est recommandé d'utiliser les éditions en lot uniquement sur les objets statiques : partenaires, produits,...
Sur l'exemple ci-contre, on a sélectionné 16 partenaires dont la position fiscale est France. Pour ce lot de partenaires, on autorise les reliquats, on paramètre le compte client sur le 411000 et on définit DelphineC comme ADV. Les champs transporteur et livraison incomplète autorisée ne seront pas modifiés car nous n'avons sélectionné ni SET, ni REMOVE.
 Il est recommandé de toujours tester l'édition de masse sur une base de test avant de modifier la base de production. Les éditions en lot ne sont pas soumises aux mêmes contraintes que les modifications manuelles : il s'agit de commandes en SQL qui peuvent passer outre certaines contraintes prévues dans les flux. De plus, selon le profil de l'utilisateur (utilisateur standard, administrateur, super-administrateur), ces contraintes changent également.
Il est recommandé de toujours tester l'édition de masse sur une base de test avant de modifier la base de production. Les éditions en lot ne sont pas soumises aux mêmes contraintes que les modifications manuelles : il s'agit de commandes en SQL qui peuvent passer outre certaines contraintes prévues dans les flux. De plus, selon le profil de l'utilisateur (utilisateur standard, administrateur, super-administrateur), ces contraintes changent également.
Par exemple, en faisant une édition en lot sur des commandes terminées pour changer la quantité, la quantité indiquée sur les BL et factures associées ne changera pas.
Si l'édition en lot n’apparaît pas dans le menu d'actions, actualiser la page puis vérifier à nouveau. Si elle n'apparaît toujours pas, vérifier que le bouton Ajouter action a bien été cliqué dans le formulaire d'édition en lot : dans ce cas, le bouton s'appellera Supprimer le bouton d'action .
Suivi des éditions
Toutes les éditions en lot sont journalisées dans le log d'édition, qui dispose de son propre sous-menu.
Éditions en lot spécifiques à des utilisateurs
Dans certains cas, on peut souhaiter activer l'édition en lot pour plusieurs utilisateurs, mais sur des champs différents. Par exemple, un responsable commercial peut souhaiter faire des modifications de masse sur tous les champs des partenaires, mais que ses commerciaux puissent modifier uniquement les conditions de règlement.
Dans ce cas, on créera deux éditions en lot sur l'objet partenaire :
-
L’une prévoyant tous les champs de l'objet avec une autorisation au manager ;
-
L’autre prévoyant une édition du champ conditions de règlement, avec une autorisation à tous les commerciaux.
Il faudra bien penser à cliquer sur le bouton Ajouter action dans les deux éditions en lot. Avec ce paramétrage, l'assistant d'édition en lot ne proposera pas les mêmes champs aux commerciaux qu'à leur manager.
Log d'édition
Le log d'édition est un journal non modifiable qui liste toutes les éditions en lot effectuées. Chaque ligne correspond à une modification en masse opérée sur un champ. Les informations stockées pour chaque ligne sont :
-
L’utilisateur à l'origine de l'édition en lot (créé par) et la date de l'action (créé le) ;
-
Le modèle (objet) et le champ concernés ;
-
L’IDs des enregistrements modifiés ;
-
La valeur technique qu'a pris l'enregistrement ; il s'agit souvent d'un identifiant.
Audit trail
Le module Audit permet de suivre l'ensemble des modifications effectuées sur certains objets en créant des règles d'audit. En cas d'erreur, on pourra ainsi vérifier qui en est à l'origine, et revenir aux états précédents si nécessaire. Ce module est très utile pour suivre les éléments critiques, dont la modification peut entraîner d'importants impacts.
Ajouts du module
Le module ajoute :
-
Un objet règle d'audit (audit_trail) ;
-
Un sous-menu Audit trail accessible par le menu Configuration / Paramètres généraux / ... qui contient deux sous-menus ;
-
Le sous-menu Règle d'audit qui permet de créer les règles ;
-
Le sous-menu Journaux d'audit qui liste les modifications opérées sur les objets suivis.
Liste des règles d'audit
-
Le nom de la règle ;
-
Le modèle (objet) suivi, car une règle d'audit permet de suivre un objet précis ;
-
L’activation de la prise en compte des modifications : si l'option est cochée, toute modification appliquée à un enregistrement de l'objet sera journalisée ;
-
L’activation de la prise en compte des suppressions : si l'option est cochée, toute suppression d'un enregistrement de l'objet sera journalisée ;
-
L’état de la règle : une règle est soit en brouillon, soit activée.la règle passe d'un état à l'autre lorsqu'on clique sur le bouton prévu à cet effet dans la vue formulaire de la règle (voir plus bas). Il n'y a pas d'état inactif : lorsqu'une règle est désactivée, elle repasse simplement à l'état brouillon.
 Formulaire des règles d'audit
Formulaire des règles d'audit
La vue formulaire se présente comme ci-contre. Outre les champs affichés dans la vue liste, une option supplémentaire permet d'activer la prise en compte des modifications en interface uniquement. Si l'option n'est pas activée, les modifications effectuées par le système sans action utilisateur, par exemple via des crons, seront également journalisées.
En dessous des champs, un bouton permet d'activer ou non la règle d'enregistrement.
Les actions définies dans les règles activées sont ensuite journalisées. la liste est consultable depuis le sous-menu Journaux d'audit. Chaque entrée de journal contient :
-
La date de l'action et l'utilisateur qui en est à l'origine ;
-
Le type d'édition effectuée (modification, suppression, ...), la méthode employée (create pour une création, set pour une modification, ...) et la règle d'audit qui a déclenché la journalisation ;
-
l'id de l'enregistrement modifié, le nom du champ modifié, la valeur qui lui a été affectée et son ancienne valeur.

Sécurité des exports
Open-Prod propose deux méthodes d'export de données, accessibles depuis le menu actions du bandeau supérieur dans les vues listes :
-
L’action Exporter exporte la totalité des données de l'objet affichés, et offre la possibilité de paramétrer les données souhaitées ;
-
L’action Exporter la vue courante exporte les données sélectionnées dans la vue, en conservant les paramètres d'affichage (tris et regroupements).
Depuis le 25 mai 2018, le Règlement Général sur la Protection des Données (RGPD) instauré par l'Union Européenne impose de tracer les données. Toute société doit être en mesure de savoir qui détient des données et depuis quand il les détient.
À cette fin, les exports d'Open-Prod sont soumis à des règles de sécurité et peuvent être tracés, de manière à identifier l'utilisateur qui exporte des données, l'objet concerné (des contacts par exemple) et la date de l'export. Par défaut, aucune règle n'est créée et seul l'administrateur de la base peut exporter des données puisque le profil administrateur n'est pas soumis aux règles d'enregistrement. C'est ensuite à lui de créer des règles de sécurité pour attribuer le droit d'exporter aux autres utilisateurs et définir quels sont les objets exportables.
Le traçage des exports se paramètre en créant des règles de sécurité ; si aucune règle traçant les exports n'existe et que l'administrateur effectue lui-même un export, l'action ne sera pas journalisée. D'autre part, l'administrateur a la capacité de supprimer l'historique des exports.
Paramétrage de la sécurité des exports (formulaire)
Les règles de sécurité d'export sont gérées depuis le sous-menu Configuration > Traçabilité enregistrements et exports > Importation et export > Règle de sécurité export. La création d'une autorisation se fait en remplissant le formulaire de création.
En-tête
Dans l'en-tête, il faut obligatoirement renseigner :
-
L’objet concerné dans le champ modèle,
-
La criticité de la règle de sécurité :
-
Aucune => les exports ne seront pas tracés.
-
Normale ou critique => les actions d’export et d’impression de rapports seront tracées pour tous les utilisateurs des groupes autorisés, tandis que les actions d’exports de vues courantes seront tracées uniquement pour les utilisateurs spécifiquement autorisés.
Cocher ensuite les options voulues :
-
Cacher les rapports : si coché, le menu Imprimer ne s'affichera pas. Cette option s'applique à tous les utilisateurs, qu'ils fassent partie des utilisateurs autorisés dans la règle ou non ;
-
Export : autorise l'export complet si coché ;
-
Export de la vue courante : autorise l'export de la vue courante si coché ;
-
Action export de la vue courante : Exporte les enregistrements de la page courante avec la limite d'affichage (généralement à 80).
-
Action export de la vue courante (en entier) : Exporte les enregistrements de la page sans limite d'affichage (la totalité).
-
Import : autorise l'import de données si coché ;
-
Tracer l'export/~ l'export de la vue courante : si l'une de ces cases est cochée, l'action d'export correspondante est enregistrée dans le journal de sécurité des exports ;
Le traçage n'est pas réalisé si la criticité est fixée sur Aucune. -
Tracer les rapports : si l'option est cochée, toute édition de rapport (Jasper ou Excel) sera consignée dans le journal de sécurité des exports.
Onglet « Autorisations »
Cet onglet permet de paramétrer les autorisations d'accès aux différentes fonctions paramétrées dans l'en-tête de la règle de sécurité. La première liste permet d'autoriser des groupes d'utilisateurs alors que la deuxième permet d'autoriser des utilisateurs individuellement.
En l'absence d'autorisation, aucun utilisateur ne peut accéder aux actions définies par la règle de sécurité, hormis l'administrateur qui n'est pas soumis aux règles de sécurité. Cependant, pour tracer les exports de l'administrateur, il faut obligatoirement créer les règles de sécurité correspondantes.
Onglet « Journaux »
Cet onglet liste les lignes du journal de sécurité générées pour la règle de sécurité affichée.
 Illustration
Illustration
Sur l'exemple ci-contre, l'utilisateur CharlesV a le droit de faire des exports complets et des exports de la vue courante des partenaires. Tous les exports seront tracés et le résultat s'affichera dans les journaux accessibles :
-
Dans le second onglet des règles de sécurité ;
-
Via le bouton Journaux sur la droite de l'écran de l'utilisateur, à partir du formulaire d'une règle de sécurité ;
Importation - Import des données CSV
L'import de données permet d'intégrer une multitude de données dans le système sans avoir à les saisir manuellement. Il est donc fréquemment utilisé au début d'un projet d'intégration d'Open-Prod pour la reprise des données existantes de l'entreprise.
L'import de données est soumis à des règles de sécurité au même titre que les exports : pour autoriser un utilisateur à importer des données, il faut donc créer les règles de sécurité correspondantes en veillant à cocher spécifiquement l'option Autoriser l'import. Pour rappel, une règle de sécurité ne concernant qu'un seul objet, il faudra créer autant de règles que d'objets sur lesquels on souhaite faire des imports.
Les imports se font généralement en deux étapes : on retraite les données du fichier source dans un fichier au format CSV, puis on l'importe dans Open-Prod. Après import, chaque ligne du fichier aura généré un enregistrement.
Préparation du fichier CSV
Open-Prod n'intègre que des fichiers au format CSV avec une virgule comme séparateur de champs et des guillemets comme caractères de délimitation de texte. Il faut donc générer un fichier .csv en utilisant ces caractères spéciaux.
Il est recommandé d'utiliser le tableur LibreCalc de la suite Libre Office, qui permet facilement de modifier les caractères séparateurs.
Dans le fichier .csv, chaque colonne correspondra à un champ d'Open-Prod. La première ligne sera le nom du champ en base données (nom technique).
L'en-tête de colonne n'est pas obligatoire, mais permettra à Open-Prod de détecter automatiquement les correspondances de champs au moment de l'import.
Pour être rigoureux, il faut utiliser le nom exact des champs et non la traduction (nom dans l'interface). Pour connaître le nom exact des champs, il faut passer en mode développeur. Dans ce mode, survoler un champ avec la souris affiche ses informations techniques dans un cadre noir (voir ci-contre). Pour chaque champ à importer, il faut ainsi identifier le nom du champ en base de données.
Pour gagner du temps et éviter les erreurs, nous vous conseillons de créer un ou deux enregistrements à la main puis de faire un export des enregistrements. Vous aurez alors les noms des champs exacts.
 Certains champs pointent vers les enregistrements d'autres objets (tables). Par exemple, dans l'objet « Partenaire », le champ Pays fait appel à l'objet « Pays ».
Certains champs pointent vers les enregistrements d'autres objets (tables). Par exemple, dans l'objet « Partenaire », le champ Pays fait appel à l'objet « Pays ».
Pour construire le fichier CSV, il faut donc créer des relations entre les tables. Pour éviter toute erreur, la meilleure méthode consiste à utiliser les clés primaires ou « id » (identifiant) des enregistrements. Dans notre exemple, pour compléter le champ Pays avec la valeur « France » dans les enregistrements de partenaires, il faudra renseigner la valeur correspondante, qui est base.fr.
Sur l'exemple ci-contre, les champs name et reference sont des champs à remplir manuellement alors que les champs currency_id/id, lang et country_id/id seront remplis par des IDs ou des valeurs définies dans le système.
Notion essentielle à retenir : les champs qui sont en relation avec une autre table sont identifiables par le « /id ».
Pour pointer vers un objet A depuis un objet B, il faut d'abord renseigner ou importer la table appelée dans A. Par exemple, il faudra créer les unités avant d'importer les produits, de manière à exporter les unités pour connaître leurs IDs.
Exporter une table
Le moyen le plus simple pour connaitre les IDs des enregistrements d'une table est d'exporter celle-ci. Rappelons que l''export de données est soumis à autorisation via des règles de sécurité.
Pour exporter des données, sélectionner les enregistrements à exporter puis cliquer sur Action / Exporter. L'assistant d'export s'affiche (cf. illustration ci-contre). Sélectionner ensuite les champs à exporter en double-cliquant sur le champ ou en sélectionnant le champ et en cliquant sur le bouton Ajouter. Les boutons Déplacer vers le haut / Déplacer vers le bas permettent d'ajuster l'ordre des champs dans le fichier exporté.
Certains types de champs ne sont pas sélectionnables lors d'un export de type « Export compatible avec l'import » :
-
Les champs fonction non stockés : leurs valeurs sont recalculées à chaque affichage, on ne peut donc pas récupérer de valeurs lors d'un export ;
-
Les champs issus d'enregistrements de many2many (listes d'enregistrements) : pour atteindre ces champs, il faut réaliser un export depuis la table correspondante.
Ouvrir un csv dans Excel ou libre office est dangereux pour les valeurs numériques commençant par un "0". Par exemple un numéro de téléphone : "0244556688" peut devenir "244556688". Faire attention à changer le format de la colonne pour la mettre de type texte.

 Import d'un fichier (format CSV uniquement)
Import d'un fichier (format CSV uniquement)
L'import du fichier s'effectue depuis le menu de l'objet correspondant. Par exemple, pour importer des clients, il faut utiliser l'action Importer depuis la vue liste des clients.
Sélectionner ensuite le fichier à importer au format CSV. Les premières lignes s'affichent à l'écran, et chaque colonne est précédée d'un menu déroulant contenant l'ensemble des champs importables sur l'objet. Si la première ligne du fichier contient le nom technique des champs, Open-Prod sélectionne automatiquement le champ correspondant dans le menu déroulant. Dans les champs non reconnus, le menu déroulant est fixé sur « Ne pas importer ». Si ces colonnes doivent être importées, sélectionner le champ correspondant manuellement. Au contraire, si une colonne ne doit pas être importée, cliquer sur pour effacer le champ sélectionné.
pour effacer le champ sélectionné.
Si le fichier importé ne contient pas d'en-têtes de colonnes, il faut impérativement décocher l'option La première ligne du fichier contient le titre de la colonne pour que la première ligne soit traitée comme un enregistrement. Dans le cas contraire, l'import commencera à la seconde ligne du fichier.
Puis, cliquer sur Valider pour tester les données. Les éventuelles anomalies détectées seront affichées en rouge à la fin du test. Pour corriger, modifier directement le fichier, l'enregistrer, et cliquer sur le bouton  à côté du nom du fichier dans l'assistant d'import pour actualiser les données. Le test peut être relancé autant de fois que nécessaire.
à côté du nom du fichier dans l'assistant d'import pour actualiser les données. Le test peut être relancé autant de fois que nécessaire.
Si le test de validation se termine avec un message « Tout semble correct » encadré en vert, cliquer sur Importer pour créer les enregistrements dans Open-Prod. Les lignes du fichier CSV font désormais partie de la base de données.
Import Excel
Le module d'import Excel permet d'importer des données depuis un fichier XLSX.
Les principaux avantages sont :
- Le déclenchement des Onchange.
- La possibilité de définir soit même la clé d'import (pas besoin de passer par les id).
- La possibilité d’importer l’état d'un enregistrement en utilisant les transitions d'un flux de travail.
- La simplicité d'utilisation (mais plus complexe à paramétrer : besoin de maîtriser les BDD et MRD).
Le module d'import repose sur les notions de :
- modèle : Définition des champs à importer en fonction d'un formatage Excel particulier.
- Traitement : Action d'import d'un fichier couplé à un modèle d'import.
Globalement, on peut se servir du module d'import Excel de 2 manières :
Méthode A : Importer les objets dans un seul modèle et faire un unique traitement qui va faire un seul commit.
Avantages/Inconvénients :
Un fichier unique peut contenir toutes les données
Mise en forme plus complexe : il faut faire appel aux numéros de lignes du fichier Excel pour construire les différents objets
Méthode B : Importer les objets dans des modèles différents puis faire un Batch. Chaque modèle sera commit à la fin de son traitement.
Méthode à privilégier
Avantages/Inconvénients :
Paramétrage et mise en forme du fichier Excel beaucoup plus facile
Meilleure lisibilité lors du traitement
Plus long à mettre en œuvre au départ : besoin de créer plus de modèles et de créer un batch. En revanche, les « briques » créées pourront ensuite être réutilisées dans d'autres imports

Ajouts du module
Le module ajoute :
Utilisation du module
1) Création d'un modèle d'import
-
Remplir l'en tête : renseigner le nom du modèle, le document modèle (facultatif : template pour la feuille d'export) et la séquence.
-
ONGLET LIGNE D'IMPORT
-
-
Ajouter une ligne d'import (cf illustration ci-dessous)
-
-
-
-
Remplir l'entête,
-
La séquence qui permettra d'ordonner les modèles d'import.
-
-
La séquence est très importante et il faut bien penser à importer les objets annexes d'abord : Par exemple : pour importer les clients et fournisseurs, il faut d'abord importer "L'objet des adresses" puis les "Partenaires". Ensuite on peut importer l'objet "Taux de TVA". Si on veut importer des contacts, il faut d'abord importer "Classe pour les fonctions des contacts" avant d'importer les contacts ("Partenaires").
-
L'objet que l'on peut rechercher par le nom technique ou par son libellé.
-
Le nom de feuille qui correspond au nom de la feuille dans le fichier Excel (évitez les caractères spéciaux, espaces, ...).
-
La ligne de départ qui indique le numéro de la première ligne à importer (ici 2 car il y a une ligne d'en tête dans le fichier XLSX).
-
La ligne de fin qui indique quelle est la dernière ligne à importer.
Si cette case n'est pas remplie, on détectera la dernière ligne automatiquement. Or, il est conseillé de la remplir pour éviter les erreurs de détection. On peut la remplir par un nombre fixe (Ex : 30 et on parcourra de la ligne de début à la ligne 30) ou par une cellule (Ex: $J1 et saisir une valeur ou une formule dans J1)
-
Ajouter des champs (cf Paragraphe suivant).
-
ONGLET OPTIMISATION :
-
-
Déclencher les Onchanges permet de déclencher le mécanisme d'héritage lorsque un champ suivi par onchange est rempli (par ex : le client dans une vente rempli tous les champs de la vente).
-
-
ONGLET REQUETE D'EXPORT (Si on veut exporter)
-
-
Le Nom du fichier correspond au nom que portera le document exporté.
-
Remplir les feuilles d'export : On peut paramétrer différentes feuille du futur fichier Excel exporté et y faire figurer les données récupérées grâce à une requête SQL. L'exemple ci-dessous nous montre l'exportation d'une vente.
-
-
Arrêter en cas d'erreur : Si cette case est cochée, l'import sera stoppé en cas d'erreur et aucune ligne ne sera commit. Si elle est décochée, dès d'une ligne sans erreur est trouvée, elle est commit, sinon elle est ignorée.
Il peut être utile de décocher cette case quand certaines cellules du fichier sont vides. Cependant, les erreurs seront ignorées donc celles dues à autre chose qu'une cellule vide aussi. Il faut donc bien parcourir les logs pour vérifier l'origine des erreurs.
Ajout des champs dans un modèle d'import
-
La séquence permet d'ordonner l'import des champs. Elle est donc très importante (Exemple lors de l'import d'un produit : Si la séquence de l'unité est inférieure à celle de la catégorie alors l'unité de la catégorie va écraser celle du produit).
-
Le champ à importer : Il faut rechercher par le libellé (pas le nom technique). Seuls les champs de l'objet sélectionné dans le modèle sont disponibles.
Parfois, deux champs peuvent avoir le même libellé. Il est alors possible d'ouvrir le modèle via le bouton carré + flèche pour vérifier que le champs choisi est le bon.
-
Déclencher le Strip : Toujours laisser coché cette case. Elle permet de supprimer, s'il y en a, les espaces avant ou après les valeurs dans les cellules du fichier XLSX.
-
Clef de modification : Elle permet de retrouver les objets déjà présents en base de données. On peut choisir quelle action effectuer en cas d'enregistrement déjà existant : Mettre à jour avec le nouvel enregistrement ou Ignorer et conserver l'ancien. (Exemple : Ici le nom de la catégorie est coché comme étant la clé et l'action choisie est la Mise à jour. Si aucune catégorie du même nom n'existe dans la bdd, elle sera créée. Sinon, elle ne sera pas re-crée mais mise à jour (avec les données du fichier XLSX)).
Il peut y avoir une ou plusieurs clés en fonction des objets (Exemple : Pour un référencement fournisseur on a besoin d'une clé sur le produit et une clé sur le partenaire pour garantir l'unicité).
-
Mode de recherche : Le mode de recherche dépend du type de champ :
-
-
Écrit : Pour les champs de type booléen, char, texte, selection, float, integer, date, time. La valeur du champs est écrite directement dans la cellule. Ce mode de recherche est utilisé pour les deux méthode A & B.
-
Pour les champs sélection, c'est le nom technique qui doit être indiqué. Pour les champs booléens, la valeur s’exprime sous la forme de 0 et 1 (cf extrait fichier XLSX ci-dessous). Pour les many2many, il faut exprimer les valeurs que l'on souhaite importer séparées par le caractère | (dans une même cellule).
Pour les champs date, un format est proposé par défaut : c'est le format qu'il faut laisser si votre date est formatée en date dans le XLSX. Sinon, vous pouvez ici indiquer le format correspondant.
-
-
La case Colonne apparaît : Il faut y écrire le numéro de colonne où se trouve le champs dans le fichier XLSX (Exemple : A).
-
-
Domaine : Pour les champs de type Many2one, One2many, Many2many. La valeur référence un object déjà présent dans la base de données. Ce mode de recherche est utilisé pour la méthode B.
-
-
Nom de l'objet apparaît : Sélectionner l'objet correspondant parmi la liste déroulante.
-
Compléter le Domaine de recherche en ajoutant une condition : Le but est de trouver une clé qui va faire appel au bon champs puisque l'on ne passe pas par les id.
-
-
-
-
Choisir le champs parmi ceux de l'objet saisi précédemment (liste déroulante).
-
Choisir l'opérateur (liste déroulante qui diffère en fonction du type de champs).
-
Saisir le numéro de colonne avec un $ (Exemple : $A).
-
-
+ Condition permet d'ajouter une nouvelle condition avec un opérateur logique ET.
+ Condition conditionnelle permet d'ajouter avec un opérateur logique OU.
-
Numéro de ligne : La valeur du champ référence un objet d'une autre feuille du fichier XLSX qui a été executé avant la feuille actuelle (Attention aux séquences). La syntaxe est alors la suivante : nom_de_la_feuille.numéro_de_la_ligne. La clé est donc dans Excel et il faut mettre la colonne dans Open-Prod. Ce mode de recherche est utilisé pour la méthode A.
-
Valeur constante écrite : On écrit directement la valeur constante dans l'encadré. Cette valeur sera importé pour tous les enregistrements. Ce mode de recherche peut être utilisé pour des champs qui sont identiques pour tous les enregistrements, ce qui évite de créer une colonne dans le fichier XLSX avec la même valeur pour toutes les lignes. Cette case fonctionne de la même manière qu'une cellule du document, elle peut être utilisée pour n'importe quel type de champ. Ce mode de recherche est utilisé pour les deux méthode A & B.
Mise en forme du fichier Excel
-
Le fichier doit être au format XLSX.
-
Voici deux exemple de fichiers :
-
-
Fichier utilisé dans les exemples sur les catégories avec différents types de champs :
-
-
Fichier avec la méthode A
On retrouve de la même manière différents types de champs. Les produits des autres feuilles sont appelés par le numéro de ligne.
Prétraitement
À la création de l'import, il est possible de définir des prétraitements pour le mode de recherche Écrit. On pourra ainsi modifier les données du fichier Excel avant de les importer. Il existe 2 types de prétraitements :
-
Remplacement d'une chaîne de caractères par une autre.
L'import prendra plus de temps car chaque ligne est analysée pour vérifier une ou plusieurs conditions du prétraitement. -
Script Python exécutant des fonctions Python sur la valeur des cellules.
Exemple : Dans le cas d'un import dans un champ type char d'une cellule qui contient un retour à la ligne, le code \n sera importé à chaque retour à la ligne. Le script suivant appliqué en prétraitement permet d'éliminer ces caractères : [values[i].replace('\n', '') for i in range(0, len(values))]
2) Traitement du modèle
Dans l'onglet Traitement d'import, créer le traitement :
-
Nom du traitement, par exemple : import nouveaux produit au 20/05
-
Importer : Sélectionner le modèle d'import à traiter parmi ceux créés.
-
Document initial : Sélectionner le fichier XLSX contenant les données.
Une fois ces 3 champs saisis il est possible d'Importer les données contenues dans le document.
Le bouton Exporter permet de d'exporter le fichier selon les paramètres que l'on a rentré dans l'onglet "Requête d'export" du modèle.
Le bouton Logs est un raccourci vers les logs de ce traitement.
Une fois importé, il est possible de Supprimer les objets créés puis de remettre en Brouillon.
3) Cas d'un batch
Le batch permet d’exécuter le traitement de plusieurs modèles à la suite.
Modèles de batch
Il faut d'abord créer un modèle de batch en choisissant un Nom et en ajoutant tous les modèles d'import que l'on souhaite exécuter.
Traitement d'un batch
Tout comme pour un traitement simple, il faut créer un traitement de batch :
-
Nom du traitement
-
Report (facultatif) : Rapport Excel à utiliser pour l'exportation.
-
Document initial : Sélectionner le fichier XLSX contenant les données si tous les traitements se basent sur le même fichier. Sinon, il faut laissez vide et insérer le bon document pour chaque modèle une fois les lignes générées.
-
Modèle de batch : Sélectionner le modèle de batch parmi ceux créés.
Une fois ces informations saisies, 3 actions sont disponibles :
- Exporter les lignes de traitement.
- Générer : génère les lignes de traitement en état Brouillon. Il faudra les importer une à une grâce aux boutons Importer (cf ci contre). Cette fonctionnalité peut être utile pour tester ligne par ligne, et si des informations doivent être modifiées avant l'import (séquence, document initial, ...).
- Générer et importer : tout est généré et importé directement en une seule étape (en se basant sur un unique fichier défini dans le document initial).
4) Import des états
On peut importer l'état d'un l'objet en ajoutant le champs État (nom technique state) dans les lignes du modèle d'import.
Si on ajoute le champ Etat :
- Si le flux de travail de l'objet est statique, on importe l'état simplement.
- Sinon, le flux de travail du modèle en question est actif, l'encadré «Configuration du workflow » s'affiche.
Si Utiliser les transitions est coché, l'objet créé parcourt les états, en empruntant les transitions par défaut, jusqu'à atteindre l'état saisi dans le fichier Excel (explications à la suite). L'intérêt est de ne pas simplement placer l'objet dans un état mais de lui faire parcourir le flux depuis le début et donc de déclencher les actions générées à chaque transition.
Utiliser ce module sans cocher l'option Utiliser les transitions revient plus ou moins à faire un import « statique » similaire à la méthode d'import csv où l'on forcerait le state.
Pour le paramétrage du workflow importeur, il faut ajouter les états par lesquels vont passer les enregistrements.
La définition des transitions par défaut dans le workflow du modèle est donc très importante et doit être faite avant de lancer l'import.
Il y a une contrainte pour la définition des transitions par défaut : il ne peut y en avoir qu'une seule entrante par état. L'algorithme part de l'état de destination (lu dans le fichier Excel) et revient jusqu'à l'état initial en empruntant la transition entrante par défaut de l'état où il se trouve.
Sur l'exemple ici, si le partenaire est importé avec l'état "Qualified", l'enregistrement va de manière transparente passer par l'état "Prospect" puis par la transition 1 (qui est celle par défaut).
5) Exploitation des logs
On retrouve les logs à plusieurs endroits :
-
Soit directement après un traitement d'import avec le bouton Logs qui va les charger avec un filtre pour ne voir que ceux du modèle en question.
-
Dans le menu Import Excel > Logs d'import.
Un log est généré pour chaque ligne traitée dans le fichier. On retrouve pour chaque log dans la vue formulaire différentes informations dont :
-
L'état : OK, OK non commit (Pas d’erreur sur la ligne en question mais une erreur plus loin a empêcher le commit et l'objet n'est donc pas créé), Erreur ou Ignorer.
-
Le modèle originaire de l'importation
-
Le type : Créer ou Mis à jour
-
La ligne qui correspond au numéro de ligne dans le fichier XLSX.
-
Un cadre message : On retrouve forcément une ligne avec les champs qui ont été lus (Champs trouvés dans le fichier XLSX). Si une erreur est détectée, le message d'erreur est indiqué à la suite.
L'utilisation des logs est particulièrement utile pour déceler les erreurs d'importation, qu'elles soient dues à une erreur dans le modèle ou une erreur dans le fichier XLSX.
Import étiquettes/lots
La reprise de données se fait le plus généralement à travers des imports CSV ou Excel. Néanmoins, pour 2 objets particuliers : les lots et les étiquettes, le module "Import étiquettes et lots" permet de créer les objets d'une meilleure manière. En effet, à travers ce module, les imports vont aussi créer le premier mouvement de l'étiquette.
Ce module crée un menu Reprise données dans lequel plusieurs sous-menus vont permettre d'importer toutes les données existantes :
-
Lots : utilisé pour la traçabilité.
-
Étiquettes : Stock des produits suivis par étiquette. Pour importer les étiquettes, il faut avoir importé les lots au préalable.
Processus de reprise de données
Étape 1 : En cliquant sur un sous-menu, le formulaire ci-contre s'affiche. Dans l'entête, il faut venir indiquer le nom de l'import. Il est conseillé de nommer l'import par la date à laquelle il a été fait. Ensuite, il faut indiquer le nom de l'utilisateur responsable de l'import et la société associée à l'import.
Étape 2 : Cliquer sur l'action Générer fichier sur la droite du formulaire.

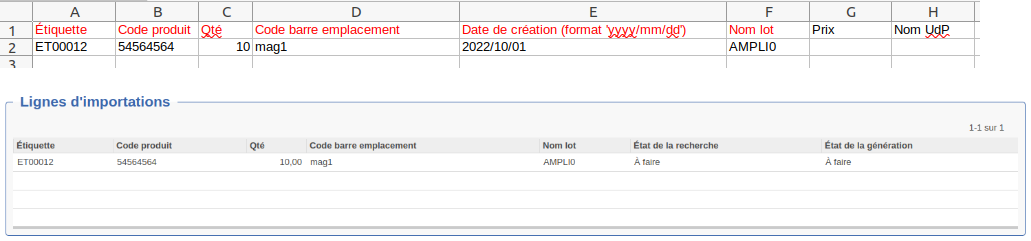 Étape 3 : Compléter le fichier avec les informations correspondantes. Le fichier contient l'ensemble des champs de l'élément, avec les champs requis en rouge.
Étape 3 : Compléter le fichier avec les informations correspondantes. Le fichier contient l'ensemble des champs de l'élément, avec les champs requis en rouge.
Étape 4 : Réimporter les données en cliquant sur Importer fichier dans les actions à droite de la vue formulaire. Les lignes viennent s'ajouter dans le cadre Lignes d'importations (ci-contre).
Étape 5 : Cliquer sur le bouton Recherche en haut à gauche du formulaire.
Étape 6 : Dans la liste, venir vérifier pour chaque ligne l'état de la recherche (voir ci-dessus). Il peut être :
-
A faire : c'est à dire qu'aucune action n'a encore été effectuée.
-
Erreur : la recherche a été effectuée mais certaines données n'ont pas été reconnue. En cliquant sur la ligne, la fenêtre ci-dessous s'ouvre. Dans le cadre Log, le message indiquant la cause de l'erreur est affiché. Il faut corriger l'erreur et relancer la recherche.
-
Terminé : la recherche s'est bien effectuée, il n'y a pas d'erreur. Tous les champs ont été reconnus.
Étape 7 : La recherche étant terminée, il faut générer l'import. Pour cela, cliquer sur Générer en haut à gauche de la vue formulaire. Comme pour la recherche, il peut y avoir trois états : A faire, Erreur, Terminé. Reprendre l'étape ci-dessus pour connaître les significations.
Si l'étape 7 est terminée, l'import est terminé, la donnée est enregistrée dans le système.
 L'opérateur utilisé pour les recherche est un '='. Il est donc sensible aux espaces et autres caractères spéciaux ainsi qu'à la casse.
L'opérateur utilisé pour les recherche est un '='. Il est donc sensible aux espaces et autres caractères spéciaux ainsi qu'à la casse.
Import d'emplacement
Particularité des imports d'emplacements
L'import d'emplacements peut en fonction de la volumétrie être fastidieux car le système doit à chaque import recalculer le parent_left et parent_right (de par la structure en arbre), ce qui peut facilement faire exploser le temps ou la mémoire nécessaire à l'import.
Cette difficulté technique est déjà gérée, en transparence pour l'utilisateur, dans un import Excel.
Pour remédier à cela, il est possible d'ajouter dans le context du bouton "Importer" : context="{'defer_parent_store_computation': True} . Cela va permettre de ne pas calculer le parent_left et parent_right à chaque nouvel emplacement. On pourra ensuite lancer une action administrateur pour les recalculer :
 Compute parent_left parent_right
Compute parent_left parent_right
stock.location
_parent_store_compute